Architecture
Grafana Mimir는 개별적으로 또는 병렬로 실행할 수 있는 수평 확장 가능한 여러 개의 마이크로서비스로 구성됩니다. 그리고 이러한 마이크로서비스를 컴포넌트라고 합니다.
Grafana Mimir 스토리지 format은 Prometheus TSDB 스토리지를 기반으로 합니다. 그리고 스토리지 format은 각 테넌트의 시계열을 자체 TSDB에 저장하여 온디스크 블록에 지속시킵니다. 기본적으로 각 블록의 범위는 2시간이며, 각 온디스크 블록 디렉터리에는 인덱스 파일, 메타데이터 파일, 시계열 청크가 포함되어 있습니다.
TSDB 블록 파일에는 여러 시리즈에 대한 샘플이 포함되어 있습니다. 블록 내부의 시리즈는 블록별 인덱스로 색인되며, 이 인덱스는 메트릭 이름과 레이블을 모두 블록 파일의 시계열에 색인합니다.
핵심 개념
- Read/Write Path: 데이터 처리를 위한 읽기 경로(Read Path)와 쓰기 경로(Write Path)를 구분합니다. 이러한 분리는 데이터 처리의 효율성을 극대화하며, 각 경로는 특정 작업에 최적화된 컴포넌트로 구성됩니다.
- Consistent Hash Rings: 클러스터 내에서 데이터를 균등하게 분배하고 고가용성을 보장하는 메커니즘입니다. 이는 클러스터의 스케일링을 용이하게 하며, 데이터 샤딩과 복제를 통한 안정성을 제공합니다.
- Storage: AWS, GCP, Azure의 객체 저장소, OpensTack Swift, 로컬 파일시스템 단일 노드을 사용할 수 있습니다.
Grafana Mimir 동작 이해하기 - The write/read path
대부분의 컴포넌트는 stateless이며 프로세스 재시작 사이에 데이터가 유지될 필요가 없습니다. 일부 컴포넌트는 stateful이며 비휘발성 스토리지에 의존하여 프로세스 재시작 사이의 데이터 손실을 방지합니다.
The write path: Prometheus, Ingester, Compactor
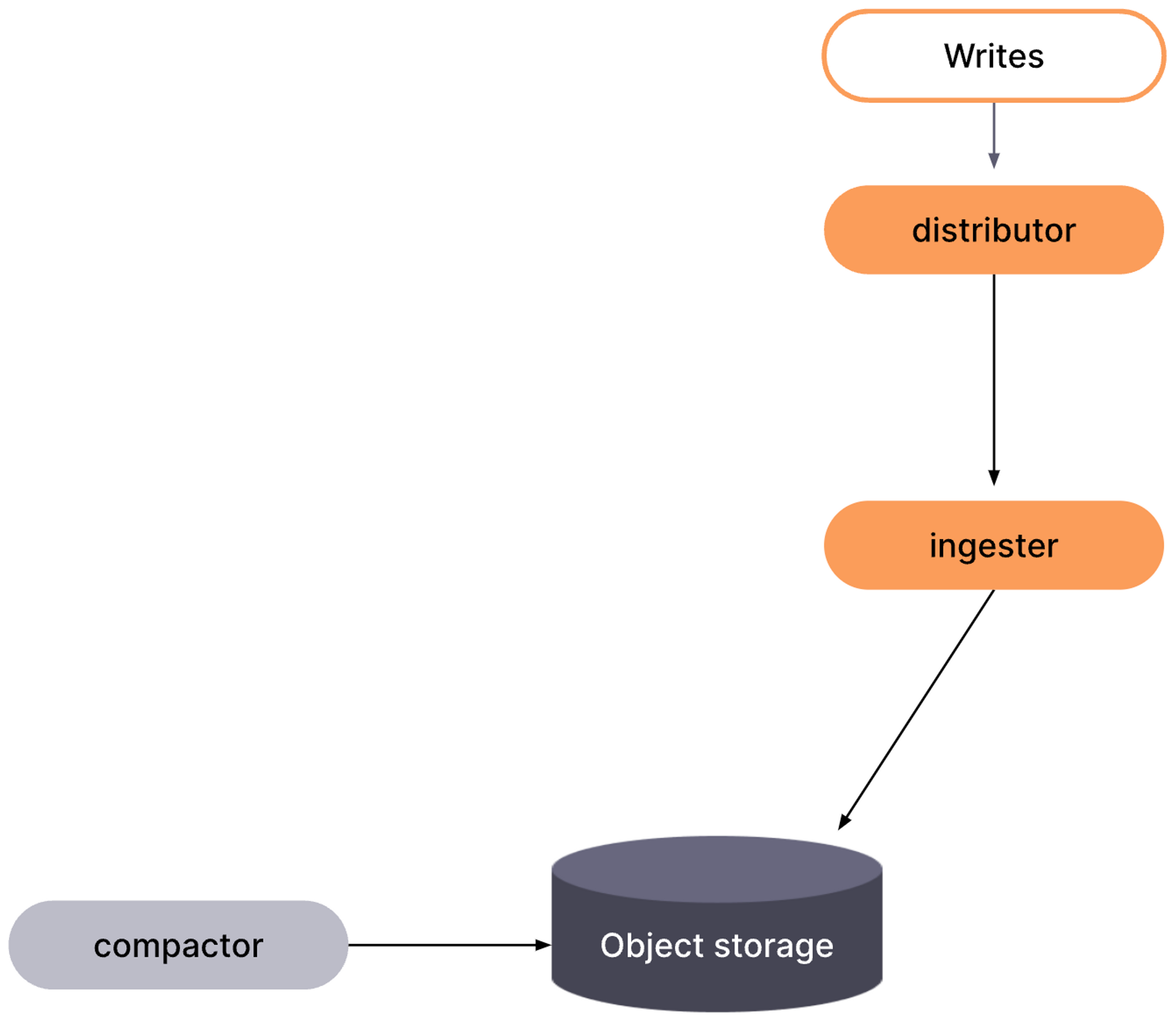
Ingester는 distributor로부터 들어오는 샘플을 수신하고, 해당 테넌트의 TSDB에 추가합니다. 수신된 샘플은 인메모리에 유지되며, write-ahead log(WAL)에 기록됩니다. Ingester가 갑작스럽게 종료되더라도 WAL은 인메모리 시리즈를 복구하는 데 도움이 될 수 있습니다. 각 테넌트별 TSDB는 해당 테넌트에 대한 첫 번째 샘플을 수신하는 즉시 각 Ingester에서 생성됩니다.
인메모리 샘플은 주기적으로 디스크로 플러시되며 새로운 TSDB 블록이 생성될 때 WAL이 잘리게 됩니다. 새로 생성된 각 블록은 장기 저장소에 업로드되고 구성된 -blocks-storage.tsdb.retention-period가 만료될 때까지 Ingester에 보관됩니다. 이렇게 하면 queriers 와 store-gateways가 저장소에서 새 블록을 발견하고 인덱스 헤더를 다운로드할 수 있는 충분한 시간을 확보할 수 있습니다.
WAL을 효과적으로 사용하고 Ingester가 갑자기 종료되는 경우 인메모리 시리즈를 복구할 수 있도록 하려면, Ingester 장애가 발생해도 살아남을 수 있는 영구 디스크에 WAL을 저장합니다. Kubernetes에서 Grafana Mimir 클러스터를 실행하는 경우, Ingester에 대한 영구 볼륨 클레임(PVC)이 있는 StatefulSet을 사용할 수 있습니다. WAL이 저장되는 파일 시스템의 위치는 로컬 TSDB 블록(헤드에서 압축된)이 저장되는 위치와 동일합니다. 파일 시스템의 위치와 로컬 TSDB 블록의 위치는 분리할 수 없습니다.
The role of Prometheus
Prometheus 인스턴스는 다양한 대상에서 샘플을 스크랩하여 Prometheus의 remote write API를 사용하여 Grafana Mimir로 푸시합니다. remote write API는 HTTP PUT request body 내에 일괄적으로 압축된 Protocol Buffer 메시지를 전송합니다.
Mimir는 각 HTTP 요청에 대한 테넌트 ID를 지정하는 헤더가 있어야 합니다. 요청 인증 및 권한 부여는 external reverse proxy에 의해 처리됩니다.
들어오는 샘플(from Prometheus)은 distributor가 처리하고, 들어오는 읽기(PromQL 쿼리)는 query-frontend에서 처리합니다.
The read path: query-frontend, querier

Grafana Mimir로 들어오는 쿼리는 query-frontend에 도착합니다. 그러면 query-frontend가 longer time ranges의 쿼리를 multiple, smaller queries로 분할합니다.
다음으로 query-frontend는 results cache를 확인합니다. results cache가 캐시된 경우 query-frontend는 캐시된 결과를 반환합니다. results cache에서 응답할 수 없는 쿼리는 query-frontend 내의 인메모리 대기열에 저장됩니다.
queriers는 대기열에서 쿼리를 가져오는 작업자 역할을 합니다.
queriers는 store-gateways와 ingesters에 연결하여 쿼리를 실행하는 데 필요한 모든 데이터를 가져옵니다.
queriers가 쿼리를 실행한 후에는 집계할 수 있도록 query-frontend에 결과를 반환합니다. 그러면 query-frontend에서 집계된 결과를 클라이언트에 반환합니다.
Components of Grafana Mimir
Distributor
Prometheus 또는 Grafana 에이전트로부터 시계열 데이터를 수신하는 stateless 컴포너트입니다.
distributor 데이터의 정확성을 검증하고 데이터가 지정된 테넌트에 대해 구성된 한도 내에 있는지 확인합니다. 그런 다음 distributor는 데이터를 배치로 나누어 여러 ingesters에 병렬로 전송하고, ingesters간에 시리즈를 분할하고, 구성된 replication 개수에 따라 각 시리즈를 복제합니다. 기본적으로 구성된 replication 개수는 3입니다.
특징
- Validation: ingester에 데이터를 쓰기 전에 수신한 데이터를 정리하고 유효성을 검사한다.
- Rate limiting: 각 테넌트에 적용되는 다음 2 가지의 속도 제한을 포함한다. Request rate, Ingestion rate
- High-availability tracker: Remote write senders가 pair로 구성되어 하나가 다운되어도 메트릭이 계속 scraped되어 Grafana Mimir에 기록된다. distributor에는 HA Tracker가 포함되어 Prometheus HA Pairs에서 인입되는 시리즈 중복을 제거할 수 있다.
- Sharding and replication: distributor는 들어오는 시리즈를 ingesters에 샤드하고 복제한다. ingester.ring.replication-factor flag를 통해 ingester의 복제본 개수를 지정할 수 있다.
- Load balancing across distributors: distributor 인스턴스 간 쓰기 요청은 랜덤하게 로드밸런싱하는걸 추천한다.
- Configuration: hash ring(distributors ring)을 형성하여 서로를 discover하고 limits을 올바르게 적용할 수 있도록 한다. 기본 구성은 memberlist를 backend로 hash ring을 구성한다.
Ingester
Ingester 컴포넌트는 들어오는 시계열 데이터를 임시 저장하고, 주기적으로 쓰기 경로의 long-term storage에 쓰고 읽기 경로의 쿼리에 대한 시리즈 샘플을 반환하는 stateful 컴포넌트입니다.
ingesters를 호출하는 모든 Grafana Mimir 구성 요소는 먼저 hash ring 에 등록된 ingesters를 조회하여 사용 가능한 ingesters를 결정하는 것으로 시작합니다.
Ingesters write de-amplification(쓰기 증폭 감소)
데이터를 큰 부하 없이 효과적으로 저장하기 위하여 사용됩니다.
Ingester는 최근에 받은 샘플을 메모리에 저장하여 write de-amplification를 수행합니다. Ingester가 수신한 샘플을 즉시 장기 저장소에 쓰면, 시스템 확장에 어려움을 겪을 수 있기 때문입니다. 따라서, Ingester는 샘플을 일괄적으로 배치하고 압축한 후, 주기적으로 장기 저장소에 업로드합니다. 이는 Mimir가 TCO가 낮은 주요 이유입니다.
Ingesters failure and data loss
Ingester 프로세스가 충돌하거나 갑자기 종료되면 아직 장기 저장소에 업로드되지 않은 모든 인메모리 시리즈가 손실될 수 있습니다. 이를 완화하는 방법은 다음과 같습니다:
- Replication: 기본적으로 각 시리즈는 3개의 Ingesters에 복제합니다. Mimir로의 쓰기 작업은 Ingesters의 과반수가 데이터를 받았을 경우에 성공한 것으로 간주됩니다.
- Write-ahead log(WAL): 시리즈가 장기 스토리지에 업로드될 때까지 들어오는 모든 시리즈를 영구 디스크에 씁니다. Ingester가 실패하면 후속 프로세스를 다시 시작하면 WAL이 재생되고 인메모리 시리즈 샘플이 복구됩니다.
- Write-behind log (WBL): 모든 들어오는 시리즈가 long-term storage에 업로드될 때까지 영구 디스크에 기록합니다. 만약 Ingesters가 실패하면, 이후의 프로세스 재시작은 WAL을 재생하고 메모리 상의 시리즈 샘플들을 복구합니다.
TSDB 블록 및 롱텀 스토리지 관리
각 테넌트별 TSDB는 첫 번째 샘플 수신 시 생성되며, 인메모리 샘플은 디스크로 주기적으로 플러시됩니다. 생성된 TSDB 블록은 장기 저장소에 업로드되며, 설정된 보존 기간 동안 Ingester에 보관됩니다. 이는 queriers와 store-gateways가 새 블록을 신속히 인식하고 필요한 데이터에 접근할 수 있도록 합니다.
Compactor
Compactor는 여러 수집기의 블록을 단일 블록으로 병합하고 중복 샘플을 제거한다. 블록 압축은 스토리지를 절약하고, 보다 효율적인 읽기 쓰기가 가능하도록 도와줍니다.
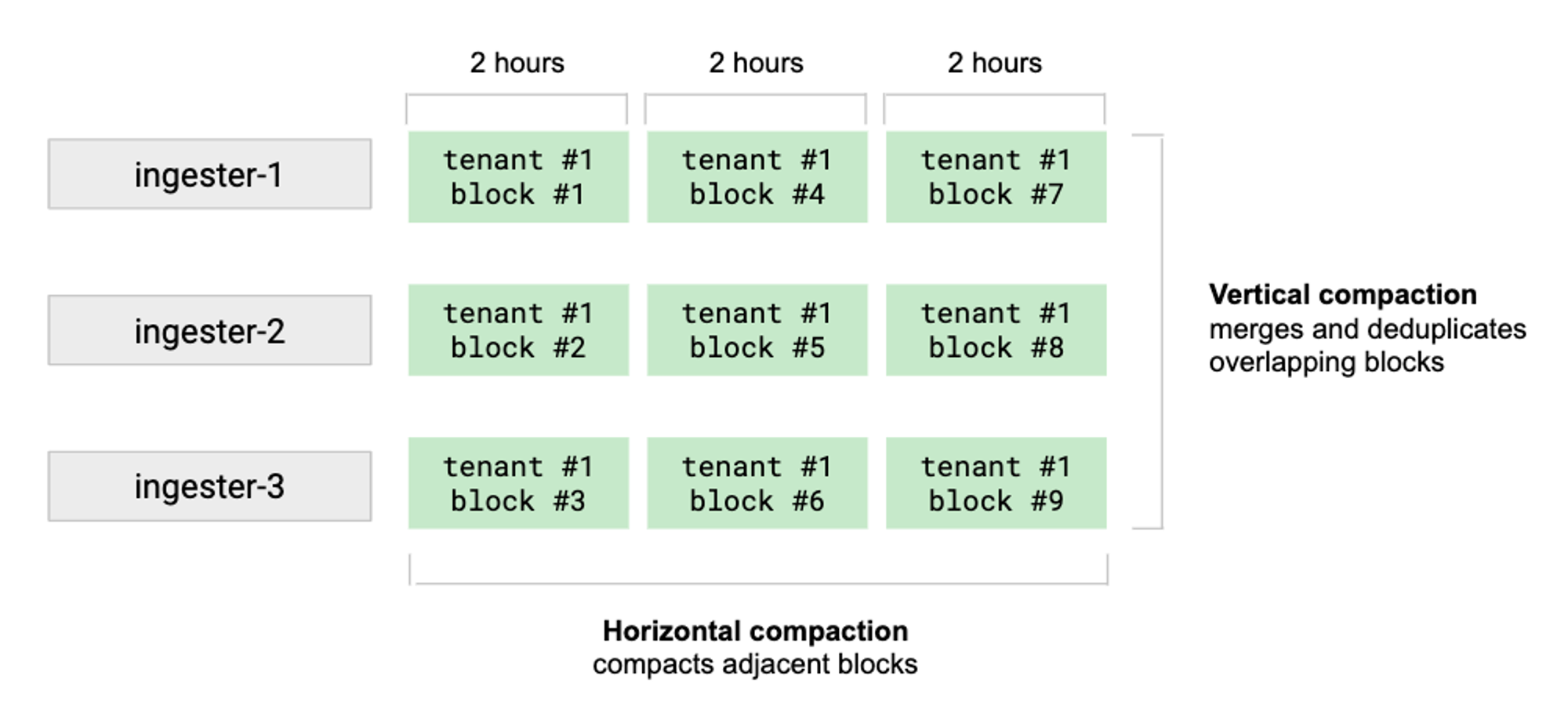
- Vertical compaction: 수집기가 동일한 시간 범위(기본적으로 2시간 범위)에 업로드한 테넌트의 모든 블록을 단일 블록으로 병합
- Horizontal compaction: vertical compaction 이후에 트리거된다. 인접한 범위 기간을 가진 여러 블록을 하나의 큰 블록으로 압축
Scaling
대규모 테넌트가 있는 클러스터의 경우 Compactor을 조정할 수 있습니다. 구성은 테넌트별로 압축할 때 Compactor가 실행되는 방식의 수직 및 수평 스케일링을 모두 지정합니다.
Blocks deletion
블록 삭제는아래 2단계 프로세스를 따라 원래 블록이 스토리지에서 삭제 됩니다.
- 원본 블록은 삭제용으로 표시됩니다(soft delete)
- 블록이 구성 가능한 -compactor.deletion-delay보다 오래 됐다고 표시되면 해당 블록은 스토리지에서 삭제됩니다(hard delete)
Blocks retention
Compactor는 Storage 보존을 강제로 시행하며, 구성된 보존 기간보다 오래된 샘플을 포함하는 블록을 장기 저장소에서 삭제합니다. 저장 보존은 기본적으로 비활성화되어 있으며, 보존 기간을 명시 적으로 구성하지 않는 한 장기 저장소에서 데이터가 삭제되지 않습니다.
Prometheus
Prometheus 인스턴스는 다양한 대상에서 샘플을 스크랩하여 Prometheus의 remote write API를 사용하여 Grafana Mimir로 푸시합니다. remote write API는 HTTP PUT request body 내에 일괄적으로 압축된 Protocol Buffer 메시지를 전송합니다.
Mimir는 각 HTTP 요청에 대한 테넌트 ID를 지정하는 헤더가 있어야 합니다. 요청 인증 및 권한 부여는 external reverse proxy에 의해 처리됩니다.
들어오는 샘플(from Prometheus)은 distributor가 처리하고, 들어오는 읽기(PromQL 쿼리)는 query-frontend에서 처리합니다.
querier
querier는 읽기 경로에서 시계열과 레이블을 가져와서 PromQL 표현식을 평가하는 stateless 컴포넌트입니다.
querier는 store-gateway를 사용하여 장기 저장소를 쿼리하고 ingester를 사용하여 최근에 작성된 데이터를 쿼리합니다.
How it works
쿼리 시점에 조회할 올바른 블록을 찾으려면 querier는 장기 저장소에 최신의 view of the bucket이 필요합니다. querier는 view of the bucket가 업데이트되도록 다음 중 하나의 작업을 수행합니다.
- 주기적으로 버킷 색인을 다운로드합니다. (버킷 인덱스를 참조)
- 주기적으로 버킷을 스캔합니다.
query-frontend

query-frontend는 querier와 동일한 API를 제공하는 stateless component로, 읽기 경로를 가속화하는 데 사용할 수 있습니다. query-frontend는 필수는 아니지만 배포하는 것이 좋습니다. query-frontend를 배포할 때는 querier 대신 query-frontend에 쿼리 요청을 해야 합니다. 쿼리를 실행하려면 클러스터 내에서 querier가 필요합니다.
query-frontend는 내부적으로 쿼리를 내부 큐에 보관합니다. 이 상황에서 querier는 큐에서 작업을 가져와서 실행하고 결과를 집계할 수 있도록 query-frontend로 반환하는 작업자 역할을 합니다.
고가용성을 위해 query-frontend 복제본을 두 개 이상 실행하는 것이 좋습니다.
store-gateway: 인덱스 헤더 관리
stateful 컴포넌트인 store-gateway는 장기 저장소에서 블록을 쿼리합니다. 읽기 경로에서 querier와 ruler는 쿼리를 처리할 때 쿼리가 사용자로부터 온 것이든 규칙(Ruler)이 평가되고 있을 때 온 것이든 상관없이 store-gateway를 사용합니다.
그라파나 관측 가능성에서는 인덱스와 데이터를 분리하거나 함께 관리하는 것이 가능하다. store-gateway는 필요한 정보를 얻기 위해 블록에 대한 인덱스 헤더(Index-heaader)를 만들고 로컬 디스크에 저장한다.
query time에 조회할 올바른 블록을 찾으려면 store-gateway는 장기 저장소에 최신의 view of the bucket가 필요합니다. store-gateway는 view of the bucket가 업데이트되도록 다음 중 하나의 작업을 수행합니다.
- 주기적으로 버킷 색인을 다운로드합니다. (버킷 인덱스를 참조)
- 주기적으로 버킷을 스캔합니다.
그라파나 관측 가능성에서는 인덱스와 데이터를 분리하거나 함께 관리하는 것이 가능하다. store-gateway는 필요한 정보를 얻기 위해 블록에 대한 인덱스 헤더(Index-heaader)를 만들고 로컬 디스크에 저장한다.
Blocks sharding and replication
store-gateway는 Blocks sharding을 사용하여 대규모 클러스터에서 블록을 수평적으로 확장합니다. Blocks은 -store-gateway.sharding-ring.replication-factor를 통해 구성된 복제본 개수에 따라 여러 store-gateway 인스턴스 간에 복제됩니다.
store-gateway 인스턴스는 hash ring과 샤드를 구축하고 링에 등록된 스토어 게이트웨이 인스턴스 풀 전체에 블록을 복제합니다.
Caching
store-gateway는 아래의 캐시 타입을 지원합니다.
ruler(optional)
recording 및 alerting rules에 정의된 PromQL 표현식을 평가하는 optional component입니다. 각 테넌트에는 recording 및 alerting rules 세트가 있으며 이러한 규칙을 네임스페이스로 그룹화할 수 있습니다.
Operational modes
Internal mode:
default, 내부적으로 querier와 distributor를 실행하고, ruler 프로세스 자체에서 recording 및 alerting rules을 평가합니다.

Remote mode:
ruler가 rules evaluation를 query-frontend에 위임합니다.
활성화하려면 -ruler.query-frontend.address CLI flag 또는 해당 YAML 구성 파라미터를 설정합니다.

Storage
각 테넌트의 시계열을 자체 TSDB에 저장함으로써 블록의 시리즈를 유지합니다. 기본적으로 블록의 범위는 2시간이며, 각 블록 디렉토리는 인덱스 파일, 메타데이터가 포함된 파일과 시계열 청크를 포함합니다.
TSDB 블록 파일에는 여러 시르즈에 대한 샘플이 들어 있습니다. 블록 내부의 시리즈는 블록 파일의 시계열에 대한 메트릭 이름과 레이블을 모두 색인(Indexing)합니다.
블록 파일을 저장할 디스크로 다음과 같은 객체 저장소가 필요합니다.
- AWS, GCP, Azure의 객체 저장소
- OpensTack Swift
- 로컬 파일시스템 단일 노드
Consistent Hash Rings
해시 링을 사용하는 컴포넌트
- Ingester: 샤딩과 시리즈를 복제합니다.
- Distributor: 비율 제한을 시행합니다.
- Compactor: 압축 워크로드를 샤딩합니다.
- Store-gateway: 장기 저장소에서 쿼리하기 위해서 블록을 샤딩합니다.
- Ruler(Option): 규칙 그룹을 평가하기 위해 샤딩합니다.
해시 링을 사용하여 구축한 기능
- 서비스 디스커버리: 인스턴스는 링에 등록된 인스턴스를 조회하여 서로를 검색할 수 있습니다.
- 하트비팅: 인스턴스는 주기적으로 링에 하트비트를 전송하여 작동과 실행 중임을 알립니다.
- 영역 인식 복제(zone-aware replication): 장애 도메인 간의 데이터 복제로, 도메인 중단 동안 데이터 손실을 방지하는 데 도움이 됩니다.
- 셔플 샤딩: 서로 다른 테넌트의 워크로드를 격리하고 공유 클러스터에서 실행되는 경우에도 각 테넌트에 단일 테넌트 환경을 제공하는 기술입니다.
https://grafana.com/docs/mimir/latest/operators-guide/architecture/about-grafana-mimir-architecture/
'Observability > Mimir' 카테고리의 다른 글
| [Mimir]What is Grafana Mimir? (0) | 2023.05.10 |
|---|
