이번 글에서는 Kubernetes의 안정성을 향상시키는 주요 설정과 구성요소에 대해 다룹니다. 이러한 설정과 구성요소는 파드의 생명주기 관리, 자원 할당 및 사용, 스케줄링 전략, 노드 관리 등 여러 범주에 걸쳐 있습니다.
특히 다음 주제에 초점을 맞춥니다.
- 파드의 생명주기 및 상태 관리: 파드의 정상 작동을 지속적으로 확인하고 필요에 따라 복구 또는 재시작하는 메커니즘.
- 스케줄링 전략: 파드가 클러스터 내에서 어떻게 배치되며, 고가용성과 효율성을 동시에 달성하기 위한 전략.
- 리소스 관리: 클러스터의 리소스를 효율적으로 할당하고 사용하는 방법.
- 노드 관리 및 안정성: 노드의 상태를 모니터링하고, 장애 발생 시 자동 복구를 위한 전략.
Pod Lifecycle
Probe
개요:
Kubernetes에서 Pod의 상태를 정기적으로 확인하는 메커니즘입니다.
설명:
Liveness, Readiness 및 Startup Probe를 통해 컨테이너가 제대로 작동하고 있는지, 준비되었는지, 시작되었는지를 확인합니다. 이를 통해 문제가 발생한 Pod를 자동으로 재시작하거나 새로운 요청을 받지 않도록 할 수 있습니다.
예시: 애플리케이션 헬스 체크
시나리오: 웹 애플리케이션의 상태를 주기적으로 확인하고, 문제가 발생하면 자동으로 재시작하려 한다.
목적: 웹 애플리케이션의 건강 상태를 보장하고 문제가 생기면 빠르게 대응한다.
해결: liveness probe를 사용하여 애플리케이션의 건강 상태를 주기적으로 검사한다.
apiVersion: v1
kind: Pod
metadata:
name: example-pod
spec:
containers:
- name: my-container
image: my-image
livenessProbe:
httpGet: # 응답의 상태 코드가 200 이상 400 미만이면 진단이 성공한 것으로 간주
path: /health
port: 8080
initialDelaySeconds: 10
periodSeconds: 5
readinessProbe:
tcpSocket: # 포트가 활성화되어 있다면 진단이 성공한 것으로 간주
port: 8080
initialDelaySeconds: 5
periodSeconds: 10
startupProbe:
exec: # 상태 코드 0으로 종료되면 진단이 성공
command:
- cat
- /tmp/initialized
failureThreshold: 30
periodSeconds: 1
Pod Scheduling
podAntiAffinity
개요:
특정 조건을 만족하는 Pod들이 동일한 토폴로지 도메인 (예: 노드, 존, 레이블 등)에서 함께 실행되는 것을 방지하는 제약조건입니다.
설명:
이 설정을 사용하면 하나의 노드에서 문제가 발생했을 때, 동일한 애플리케이션의 모든 인스턴스에 영향을 미치지 않도록 분산시켜 가용성과 성능을 향상시킬 수 있습니다.
예시: 동일한 데이터 센터 내의 랙(Rack) 배치
시나리오: 대규모 데이터 센터에서 각 랙에는 여러 노드가 있으며, 각 랙은 독립적인 전원과 네트워크 스위치를 가지고 있다.
목적: 한 랙에 문제가 발생하면 그 랙에 있는 모든 노드가 영향을 받을 수 있다. 따라서 고가용성을 위해 특정 애플리케이션의 여러 인스턴스를 서로 다른 랙에 배치하려 한다.
해결: podAntiAffinity를 사용하여 특정 애플리케이션의 Pod들이 동일한 랙에 위치하지 않도록 한다.
apiVersion: v1
kind: Pod
metadata:
name: example-pod
spec:
containers:
- name: my-container
image: my-image
affinity:
podAntiAffinity: # 4. 해당 노드에 Pod를 배포하지 마라
requiredDuringSchedulingIgnoredDuringExecution: # 3. 가급적(preferred), 반드시(required)
- labelSelector:
matchExpressions: # 2. 해당 라벨을 가진 pod가 이미 실행 중이라면
- key: app
operator: In
values:
- my-app
topologyKey: kubernetes.io/hostname # 1. 해당 라벨을 가진 노드에
topologySpreadConstraints
개요:
지정된 토폴로지 도메인에서 Pod들의 균등한 분포를 보장하는 것입니다. 즉, Pod의 수가 각 토폴로지 도메인에서 균등하게 분포되도록 합니다.
설명:
이를 사용하면 특정 레이블을 가진 pod들의 분포가 토폴로지 도메인(예: 노드, 존, 레이블 등) 마다 균일하게 유지되어, 특정 영역에 장애가 발생해도 애플리케이션의 가용성이 유지될 수 있습니다.
예시: 다중 존(Multi-Zone) 배치
시나리오: 클라우드 제공 업체에서 제공하는 존 기반의 클러스터에서 작동하는 애플리케이션.
목적: 특정 존에 장애가 발생해도 애플리케이션의 가용성을 유지하기 위해, 애플리케이션의 인스턴스를 여러 존에 균등하게 분포시키고 싶다.
해결: topologySpreadConstraints를 사용하여 애플리케이션의 Pod들이 여러 존에 균등하게 분포되도록 한다.
apiVersion: v1
kind: Pod
metadata:
name: example-pod
spec:
containers:
- name: my-container
image: my-image
topologySpreadConstraints:
- maxSkew: 1 # 노드 간에 허용되는 최대 차이를 지정
topologyKey: kubernetes.io/zone # 분산 제약 조건을 적용할 기준 키를 지정, 여기서는 노드의 가용영역을 기준
whenUnsatisfiable: ScheduleAnyway # 제약 조건을 만족시키지 못할 경우 어떻게 처리할지를 지정
labelSelector:
matchLabels:
app: my-app
nodeAffinity - Topology Affinity
개요:
Pod가 특정 노드 또는 토폴로지 도메인에 속해야 할 경우, 토폴로지 어피니티를 사용하여 해당 제약 조건을 설정할 수 있습니다.
설명:
이를 통해 성능, 가용성 또는 기타 요구 사항에 따라 Pod가 특정 노드에만 배치되거나 특정 토폴로지 영역에서만 실행되도록 제어할 수 있습니다.
예시: 메모리가 높은 노드에만 pod를 스케줄링
Pod가 hardware-type=high-memory 레이블을 가진 노드에만 배치되도록 토폴로지 어피니티를 설정하고 있습니다. 따라서, Pod는 high-memory 토폴로지 영역에 속한 노드에만 스케줄링될 수 있습니다.
시나리오: 메모리가 많은 노드와 일반 노드가 데이터 센터에 혼합되어 있다.
목적: 메모리 집약적인 애플리케이션을 메모리가 많은 노드에 배치한다.
해결: nodeAffinity 설정을 사용하여 메모리 집약적인 애플리케이션을 높은 메모리 노드에만 스케줄링한다.
apiVersion: v1
kind: Pod
metadata:
name: memory-intensive-pod
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: hardware-type
operator: In
values:
- high-memory
containers:
- name: memory-intensive-container
image: memory-intensive-image
Resource Management
서비스 품질 클래스(QoS)
Configure Quality of Service for Pods https://kubernetes.io/docs/tasks/configure-pod-container/quality-service-pod/
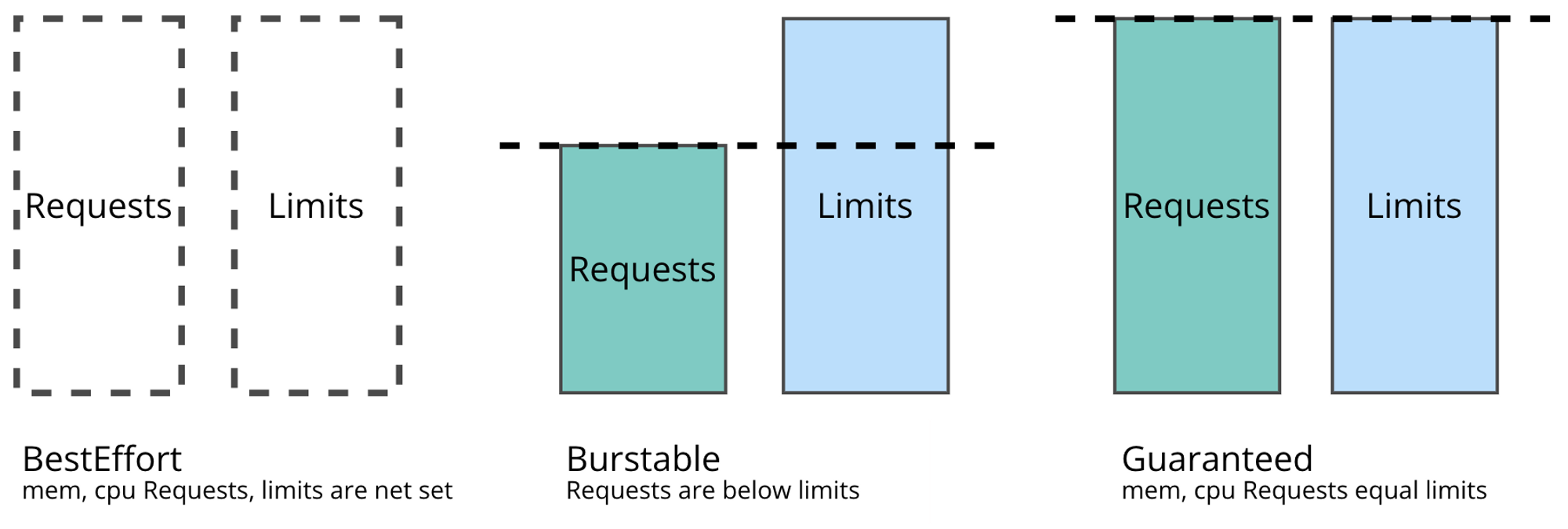
개요:
Pod의 리소스 요청 및 제한을 기반으로 한 서비스 품질을 정의합니다.
설명:
Guaranteed, Burstable, BestEffort 세 가지 클래스로, 리소스 확보와 스케줄링 우선순위에 영향을 줍니다. 우선순위 Guaranteed > Burstable > BestEffort
Guaranteed: 다른 Pod들에 의해 리소스를 선점당하지 않으며, 노드의 리소스를 보장받는 우선 순위가 높은 Pod에 사용됩니다.
Burstable: Pod는 요구 사항을 충족하는 경우에는 노드의 리소스를 보장받지만, 다른 Pod들이 리소스를 요청할 경우 리소스를 선점당할 수 있습니다.
BestEffort : 다른 Pod들이 리소스를 요청하는 경우에는 할당된 리소스가 제한적일 수 있습니다. BestEffort 클래스는 클러스터의 남은 리소스를 활용하고, 높은 우선 순위를 가지는 Pod들에게 할당될 수 있는 제한적인 리소스를 사용합니다.
예시: 우선 순위가 높은 애플리케이션
시나리오: 서로 다른 우선 순위의 애플리케이션을 동일한 클러스터에서 실행하고 있다.
목적: 중요한 애플리케이션에 자원을 보장하며, 다른 애플리케이션에 영향을 주지 않는다.
해결: QoS 클래스를 사용하여 pod에 자원 우선순위를 부여한다.
apiVersion: v1
kind: Pod
metadata:
name: guaranteed-pod
spec:
containers:
- name: guaranteed-container
image: some-image
resources:
requests:
memory: "1Gi"
cpu: "500m"
limits:
memory: "2Gi"
cpu: "1"
HPA (Horizontal Pod Autoscaler)
개요:
CPU, 메모리 사용량 등의 메트릭을 기반으로 Pod의 인스턴스 수를 자동으로 조정하는 기능입니다.
설명:
부하가 증가하면 자동으로 Pod의 수를 늘려서 처리능력을 향상시키며, 부하가 감소하면 자동으로 줄여 리소스를 효율적으로 사용합니다.
예시: 트래픽 증가 시 자동으로 scale out
시나리오: 웹 애플리케이션에 대한 트래픽이 변동적이다.
목적: 트래픽 증가 시 자동으로 pod 인스턴스를 늘려서 요청을 처리한다.
해결: HPA를 설정하여 CPU 사용률 또는 다른 메트릭을 기반으로 pod 인스턴스를 자동으로 조절한다.
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: web-app-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: web-app
minReplicas: 3
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 80
Node Management
PodDisruptionBudget
개요:
동시에 중단될 수 있는 Pod의 최대 수나 비율을 지정하는 설정입니다.
설명:
유지보수 또는 업데이트 중에도 서비스 중단을 최소화하고 애플리케이션의 가용성을 유지할 수 있습니다.
예시: 높은 가용성이 필요한 애플리케이션
시나리오: 회사의 핵심 웹 애플리케이션은 높은 가용성이 필요하다.
목적: 유지 보수나 업데이트 중에도 항상 최소한의 파드 인스턴스가 작동하도록 보장한다.
해결: PodDisruptionBudget를 설정하여 동시에 다운되어서는 안 되는 최소 파드의 수나 비율을 지정한다.
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: my-pdb
spec:
minAvailable: 2 # 동시에 다운될 수 없는 파드의 최소 개수
selector:
matchLabels:
app: my-app
Karpenter
개요:
Karpenter는 여러 클라우드 공급자와 통합되며, 실시간으로 노드를 프로비저닝하고 사용되지 않는 노드를 종료하여 클러스터의 효율성을 향상시킵니다.
설명:
실제 리소스 사용을 기반으로 클러스터의 크기를 자동으로 조정하여 리소스 사용 효율성을 최적화합니다.
Karpenter는 파드 요구 사항에 따라 동적으로 노드를 프로비저닝합니다.
왜 필요한가?
- 리소스 요청이 많아진다면, Karpenter는 자동으로 노드를 확장하여 사용자의 요청을 처리할 수 있습니다.
- 노드의 활용도를 극대화하며 리소스 낭비를 최소화합니다.
예시: 클러스터의 리소스를 모두 사용하여 pod가 pending 상태로 scale out을 하지 못하고 있다.
시나리오: 클러스터 내의 파드 요청이 증가하여 더 많은 노드가 필요하다.
목적: 파드 요청에 따라 노드를 자동으로 프로비저닝하고, 사용하지 않을 때는 자동으로 종료하여 비용을 절약한다.
해결: Karpenter 프로비저너를 설치하고 설정하여 파드 요청에 따라 자동으로 노드를 프로비저닝하도록 한다.
'Cloud-native > Kubernetes' 카테고리의 다른 글
| [Kubernetes]Sealed secrets - A Kubernetes controller and tool for one-way encrypted Secrets (0) | 2023.07.23 |
|---|---|
| [Kubernetes]How to use PV and PVC in kubernetes with GKE (0) | 2022.12.04 |
| [Kubernetes]How to create Kubernetes Secret from Json/Yaml/Literal (0) | 2022.07.08 |
| [Kubernetes]What is Annotation in Kubernetes? (0) | 2022.06.06 |
| [Kubernetes]How to use Label and Selector - Example (0) | 2022.06.05 |